As a newly appointed information security leader, the first few months are critical to setting the foundation for a successful security program. During this period, it’s important to prioritise understanding of the organisation’s current security posture, establishing a baseline, and implementing quick wins to improve security.
Here are three key steps that you should consider in the first 90 days:
Determine what we are going to measure ourselves against
Identify the organisation’s goals and objectives, and align it with the right security framework establishing a clear set of benchmarks and a common language around security, ensuring that everyone in the organisation is working towards the same goals.
Check where we’re at; take a couple of assesments
Once you have a clear understanding of the organisation’s goals, conduct a series of assessments to evaluate the current state of the security program.
Start implementing prioritised security initiatives and establish baseline
Starting a few key initiatives during their first 90 days is important. This can include low-hanging fruit, such as improving multi-factor authentication coverage, streamlining the patch management processes, and enhancing employee security awareness training. By implementing these early on, you can establish a baseline for measuring progress and building momentum towards larger, more complex security projects.
What is a security framework?
Similar to how a motherboard serves as the foundation for a PC’s construction, a security framework provides the structure for implementing a comprehensive security program. By adhering to a security framework, organisations can ensure that they address all necessary security areas and implement security measures that are suitable and effective for their unique requirements.
While building a computer, it may be tempting to design your own motherboard, or create a customised framework. However, in the realm of security, it is generally not recommended to create your own framework. If you create your own security framework instead of using an industry-approved or government-approved one, auditors may question the organisation’s decision during audits, potentially leading to increased scrutiny and scrutiny of the organisation’s overall security posture. These established frameworks have been developed through years of research and experience, and are recognised as industry standards.
There are three main types of security frameworks that organisations can use to establish a comprehensive security program:
Control frameworks
Program frameworks
Risk frameworks
Control frameworks
These frameworks offer a catalog of security controls that organisations can use to address specific security risks. Examples include the Center for Internet Security (CIS) 18 Critical Security Controls and the National Institute of Standards and Technology (NIST) Special Publication 800-53.
Program frameworks
These frameworks provide a holistic approach to security program development, covering all aspects of the program including governance, risk management, compliance, and incident response. Examples include ISO 27001 and the NIST Cybersecurity Framework (CSF)
Risk frameworks
These frameworks provide a structured approach for identifying, assessing, and prioritising security risks. Examples include the Factor Analysis of Information Risk (FAIR), ISO 27005, and the NIST 800-39.
Continuing with the analogy, building a computer requires selecting the right components and assembling them correctly. This is where control frameworks come in, these provide a catalog of computer parts (security controls) from which you can assemble a computer.
However, having the right parts isn’t enough to build a functioning computer. You also need a manual that outlines the steps for assembling the parts correctly. The program framework is like a manual that gives step-by-step instructions on how to assemble the computer using the parts catalog. It provides guidance on the order in which components should be installed, how they should be connected, and how they should be configured.
Finally, the risk framework is used to protect the computer from potential threats. This involves identifying potential risks and vulnerabilities, assessing their potential impact, and implementing measures to mitigate or eliminate them. The risk framework also provides feedback for continuous improvement to build better parts, or security measures, for protecting the business.
Closing
In summary, just like building a computer, establishing a comprehensive security program requires selecting the right components (control frameworks), following a step-by-step guide (program frameworks), and protecting against threats (risk frameworks). By using these different types of frameworks together, organisations can establish a strong security foundation, comply with industry regulations, and defend against potential cyber attacks.
As a mobile developer, it’s prudent to assume that once data reaches a phone, it’s already at risk of compromise. Proper data security measures depend on the sensitivity of the information being stored. It’s crucial to comprehend the consequences of losing any data you choose to save on a device due to a silent jailbreak or root exploit.
Guiding Principle
Do not store data unless absolutely necessary. Do not store data for longer than you need.
Data classification
Data classification
Type of data stored on the client side
GDPR Classification
Volume of data
Higly Sensitive
Payment data or sensitive personal data of the owner of the device or individuals other than the owner.
Sensitive Personal
One or many individuals
Sensitive
Personal data of individuals other than the owner of the mobile device.
Personal
Many individuals
Consumer grade
Personal data that relates to the owner of the device only.
Personal
One individual
Highly sensitive data
Highly sensitive data refers to any information that may be stored on the device related to identifiable individuals other than the owner of the mobile device. This category also encompasses sensitive personal data (as classified by GDPR) but also payment data like credit cards and user passwords.
Example: Payment card data, passwords, genetic data, biometric data, health information, sexual orientation, any sensitive personal data related to one or many users.
Sensitive data
Sensitive data refers to any information that, if compromised, could potentially put at risk not only the owner but also other users of the service.
Example: Shared secrets, shared API keys, personal data of individuals other than the owner of the mobile device.
Consumer grade data
Consumer grade data refers to any remaining data that may be stored on the device to enable the application to function and data related to the owner of the device.
Example: User settings, user preferences, tickets, bookings, transactions, reference data, default payment method, user related configuration, any data that is related to the owner of the device only.
Storing highly sensitive data
Storing highly sensitive data on mobile devices should be avoided at all costs. The preferred method is to store data securely on the server side.
However, if client-side storage is absolutely necessary, the only acceptable approach is to encrypt the data using a secret key that remains with the user at all times. This requires asking the user for a passphrase during the first use. The passphrase should be fed into a key derivation function, such as PBKDF2, along with a random salt to generate a secure key for encryption. It’s important to note that the passphrase cannot be stored on the device or within the source code. Additionally, the encryption algorithm must be industry-tested and cannot rely on the standard iOS encryption. While the key may be cached in memory, it should be securely erased after decryption. The passphrase must be complex, alphanumeric and not a 4 digit PIN.
Open source products like SQLCipher with built-in key derivation have a good security track record, but proper key management is crucial, as outlined above. Any implementation must be subjected to a thorough security review.
It should be noted that user passwords fall within the highly sensitive data category and storage on the client-side is prohibited. Instead, token-based authentication can be used as it relies on exchanging the password for an access token and effectively downgrades the sensitivity of the data to the consumer grade.
Storing sensitive data
To prevent putting multiple users at risk, sensitive information should not be stored on mobile devices. Permanent storage of sensitive data owned by your organisation should be avoided unless absolutely necessary, such as for offline operations. Unprotected storage of sensitive information or data in an easily accessible location on the device may lead to unintended data leakage, making it susceptible to theft and resulting in fraud and reputational damage. The default iOS encryption and Keychain have inherent weaknesses, such as relying on the user’s device passcode, which is often a 4-digit PIN. Therefore, sensitive data should not solely rely on the default iOS encryption, and a defense-in-depth mechanism is necessary to protect the data. The recommended approach is to encrypt the data with a secret key derived from a passphrase provided by the user during the first use. If the passphrase cannot be provided each time the user requires access to sensitive data, custom obfuscation can be implemented to reduce the number of attack vectors.
As a developer, it’s crucial to comprehend the potential consequences of losing sensitive data and for the business to accept the risk. To mitigate this risk, obfuscation techniques can be used to make it harder for attackers to access the data. These techniques may include custom encryption using tools like
Common Crypto
code obfuscation
iOS encryption
application shielding
anti-jailbreak measures
anti-debugging techniques
However, it’s essential to keep in mind that these techniques do not guarantee complete protection, and additional measures such as thorough security reviews and a defense-in-depth approach should also be implemented.
Instead of generating a random encryption key and storing it on the device (e.g., in Keychain), a more secure approach is to derive the key each time it is required based on multiple constituents:
A partial secret stored in the code
A randomly generated salt stored securely in the Keychain
The device’s unique hardware identifier, such as its UDID, UUID, MAC Address, Advertising Identifier or Vendor Identifier
Although obfuscation itself doesn’t add any significant security measures, it can still be useful in making it more challenging for potential attackers to understand the app’s operation. This can potentially lower the number of attack vectors and make the app less vulnerable to exploitation.
Example approach to deriving an encryption key in an obfuscated manner
1. Store a partial secret in the source code:
// static NSString *myKey = @"eif1Queaxe" //avoid - can be easilly found when strings command is run against the binary
unsigned char myKey[] = { 0x65, 0x69, 0x66, 0x31, 0x51, 0x75, 0x65, 0x61, 0x78, 0x65 } // preferred
2. Generate a random salt and store it securely in Keychain. The most secure way to generate the salt is to use arc4random():
4. Combine these two by XORing the hard coded secret key with SHA1 of the device’s MAC address:
#include <CommonCrypto/CommonCrypto.h>
unsigned char myKey[] = { 0x65, 0x69, 0x66, 0x31, 0x51, 0x75, 0x65, 0x61, 0x78, 0x65 }
// Get the SHA1 of the devices MAC Address, to form the obfuscator.
unsigned char obfuscator[CC_SHA1_DIGEST_LENGTH];
// Fetch the device's MAC address
NSString *deviceMac = [ myObject query_mac ];
CC_SHA1(deviceMac.bytes, (CC_LONG)deviceMac.length, obfuscator);
// XOR the MAC address against the key to from the real secret
for (int i=0; i<sizeof(obfuscatedSecretKey); i++) {
actualSecret[i] = myKey[i] ^ obfuscator[i];
}
5. Use the calculated secret from the previous step to derive the encryption key:
#import <CommonCrypto/CommonKeyDerivation.h>
NSData* mySecret = [actualSecret dataUsingEncoding:NSUTF8StringEncoding];
// Ask CommonCrypto how many rounds to use so the process takes 0.1s ?
int rounds = CCCalibratePBKDF(kCCPBKDF2, mySecret.length, salt.length, kCCPRFHmacAlgSHA256, 32, 100);
unsigned char key[32];
// Use PBKDF2 to derive the key
CCKeyDerivationPBKDF(kCCPBKDF2, mySecret.bytes, mySecret.length, salt.bytes, salt.length, kCCPRFHmacAlgSHA256, rounds, key, 32);
NSData* keyData = [NSData dataWithBytes:key length:32];
6. As soon as the key is no longer necessary make sure to overwrite it:
memset([ keyData bytes ], 0, [ keyData length ]);
The symmetric encryption key can be generated each time an encryption or decryption operation is required using the method described above. The salt, which is stored in the keychain, is unique to the device, and if it’s lost, the encrypted data will become unreadable, effectively becoming a de facto key in this scenario.
Alternatively, the salt can be derived from the device’s MAC address, and the secret hidden in the source code can be directly used in PBKDF2. This approach would eliminate the need for anything to be stored in Keychain. However, this would also mean that anyone who understands the process could decrypt the data from any device as long as they have the device’s MAC address or can brute force it. If other variations of the above approach are used, such as XOR with a known class name, it can further complicate the process.
Jailbroken devices
It is highly recommended for applications to implement a jailbreak detection mechanism to enhance their security posture. A jailbroken device is less secure because it can bypass many of the built-in security mechanisms and protections that are designed to protect the device and its data. By detecting whether the device has been jailbroken, an application can respond accordingly e.g. by deleting all its Keychain items and sensitive data files and inform the user.
One common approach to jailbreak detection is to look for the presence of known jailbreak files, directories, or system calls that are typically associated with jailbreaking. If any of these are detected, the application can take appropriate action, such as refusing to run or deleting sensitive data.
12345
if ([[NSFileManager defaultManager] fileExistsAtPath:@"/bin/bash"] ||
[[NSFileManager defaultManager] fileExistsAtPath:@"/Applications/Cydia.app"] ||
[[NSFileManager defaultManager] fileExistsAtPath:@"/private/var/lib/apt"]) {
// this device is jailbroken
}
It is also important to note that jailbreak detection is not foolproof, as there are many ways for a determined attacker to bypass these measures.
t is recommended to use commercial jailbreak detection solutions as they are constantly updated to detect new ways of bypassing security measures. relying solely on a single method may not be sufficient to detect all possible jailbreaks. Commercial solutions typically provide a more comprehensive approach to detecting jailbreaks by combining multiple methods and techniques to ensure a higher level of accuracy.
Anti Debugging
Any attempt to obfuscate the application code should be complemented with counter-tampering mechanisms to ensure the integrity of the app’s execution. One such mechanism is process trace checking:
App shielding uses a combination of techniques such as code obfuscation, encryption, and runtime checks to detect and prevent malicious activities. There are third-party solutions that offer app shielding as a service.
Storing consumer grade data
Apple’s iOS offers a range of built-in data protection mechanisms that are generally sufficient for safeguarding consumer-grade data, i.e., any information related to the device owner. To ensure optimal security, it is recommended to store such data in secure containers that leverage Apple-provided APIs.
iOS device encryption
Although iOS does have an encrypted file system, it is typically unlocked from the moment the operating system boots up because both the OS and applications need access to it. This means that even when the device is locked with a PIN or passphrase, the encrypted file system can still be read by the operating system. As a result, your data is not encrypted using an encryption method that relies on your password for the most part.
Keychain
The Keychain is a secure database maintained by Apple that stores sensitive information, encrypted using a passphrase, which may be a simple 4-digit numeric passcode.
While the Keychain has several attributes, only two are recommended. It is advisable to set these attributes explicitly rather than relying on the default settings provided by iOS:
Attribute
Data is
Note
kSecAttrAccessibleWhenUnlocked
Only accessible when the device is unlocked.
Default
kSecAttrAccessibleWhenUnlockedThisDeviceOnly
Only accessible when the device is unlocked. Data is not migrated via backups.
Prefered
The usage of the remaining keychain attributes should be carefully considered and generally avoided.
For example, iOS defaults to a simple four-digit numeric passcode for the keychain passphrase. To deduce this passcode in iOS 8 and access the file system, an attacker would need to iterate through all 10,000 possible combinations. With root code execution on the device, this would take about 20 minutes, and could be done in the kernel without triggering a wipe after too many failed attempts.
However, recent hardening efforts in iOS 8 have made it no longer feasible to get root execution unless one possesses a rare low-level 0day exploit. Additionally, there are mitigation controls in place, such as Find My iPhone, which allows users to remotely locate, lock, and wipe a lost device.
Core Data
To safeguard larger or more diverse consumer data, iOS offers the default data protection API, which features four file protection classes similar to keychain protection classes. However, the three most significant classes are:
Complete (locked when the device is locked)
Complete until First Authentication (locked, until the user’s unlocked the device once after the most recent reboot)
None (no additional protections)
12345
// Make sure the database is encrypted when the device is locked
NSDictionary *fileAttributes = [NSDictionary dictionaryWithObject:NSFileProtectionComplete forKey:NSFileProtectionKey];
if (![[NSFileManager defaultManager] setAttributes:fileAttributes ofItemAtPath:[storeURL path] error:&error]) {
// Deal with the error
}
User passwords
Storing a user’s password on the client-side is a critical security concern and should be avoided. Instead, applications should use token-based authentication to exchange the user’s password for an access token. Once the token is obtained, the password should be securely removed from memory. To store authentication tokens, iOS Keychain APIs should be used. These tokens can be revoked in case of a lost or stolen device or a compromised session. Unlike passwords, which can be reused by users to access other services, tokens are unique to the application.
Device passcode
As explained above the default iOS encryption keying is tied to user’s device passcode. It is important to ensure that the application detects when the passcode is not in effect and inform the user about risks before storing any data e.g. train tickets. Starting from iOS 8 it is possible to programmatically detect whether the passcode is enabled or not. See https://github.com/liamnichols/UIDevice-PasscodeStatus for more details.
Web Storage is a technology for client-side storage that enables web applications to save data on the user’s computer. As a considerable amount of information regarding the use of sessionStorage and localStorage already exists so we will not cover it here but only forcus on security. Web Storage was developed as a substitute for cookies, but has certain limitations that we’ll delve into that make it a non-starter for most use cases.
TL;DR
Do not store any personal data or authentication data in Web Storage. To maintaindata security, it is imperative not to send it to the client for storage. Use cookies to store authentication data at the client side. Do not store data for longer than you need.
In cases where Web Storage must be utilised, it is essential to be well-informed about the security and functional implications of this storage mechanism. Keep in mind that any data originating from the client-side is considered untrustworthy. You may encrypt data before saving it on the client-side, but this approach may entail costs that outweigh the benefits of storing it the server side.
How the data is stored
The storage mechanism for data can vary across browsers, and the HTML5 standard does not specify any particular implementation guidelines. This means that there is no requirement to ensure that sessionStorage is stored only in memory. Firefox, for instance, utilizes SQLite as a backend to store data on disk, regardless of whether localStorage, sessionStorage, IndexedDB, or WebSQL is chosen. On the other hand, Chrome uses a single browser cache file per Fully Qualified Domain Name (FQDN). The implementation of sessionStorage in other browsers may differ. It is important to note that unlike session cookies, sessionStorage does not offer any guarantees regarding non-volatility, and data is not encrypted when it is at rest.
Persistence
The behavior of sessionStorage is such that it only persists as long as the window or tab from which it originates remains open. In contrast to session cookies, which expire when the browser is closed (not just the tab), this can render sessionStorage unsuitable for storing session IDs/tokens in situations where users frequently use multiple tabs within a single-page application.
On the other hand, localStorage can be saved indefinitely, or until the user manually deletes it. However, most users are not familiar with how to do this. Additionally, the persistence of localStorage is not guaranteed. For example, Apple has relocated the location of localStorage files to a cache folder, which may be subject to periodic cleanup on iOS devices.
Private browsing
When it comes to Web Storage, Safari has a strict policy of not allowing it in Private Browsing mode. Any attempts to set an item using localStorage.setItem during or prior to a private browsing session will result in a null return value.
In contrast, Chrome and Opera will return items that were set prior to the start of a private (“incognito”) browsing session, but during that session, localStorage will behave like sessionStorage, i.e., only items set during that session will be accessible. However, localStorage will function like localStorage for other private windows and tabs.
Firefox behaves similarly to Chrome in that it will not retrieve items set on localStorage prior to the start of a private browsing session. During private browsing, it treats localStorage like sessionStorage for non-private windows and tabs, but like localStorage for other private windows and tabs.
Security
Web Storage is easily accessible via JavaScript on the same domain. This implies that any JavaScript code running on a website can potentially gain access to web storage, making it vulnerable to Cross-Site Scripting attacks. This vulnerability can be exploited by attackers to:
Steal all data stored in Web Storage.
Inject malicious data into Web Storage.
If you choose to utilize Web Store, it’s important to be aware that harmful data can potentially be injected into web storage through JavaScript. Therefore, any application using this platform must implement measures to handle untrusted data appropriately. For example, in the event that a user is deceived by a phishing attempt and clicks on the link below:
Third-party JavaScript code included on a website can also access Web Storage, creating additional security concerns.
Any authentication mechanism that relies on Web Storage can be bypassed by a user with local privileges on the machine where the data is stored.
Web Storage does not have a way to restrict the visibility of an object to a specific path, unlike cookies e.g. a third party markeding app on example.com/app can access anything from example.com/.
Web Storage is not encrypted on the client side, and some browsers may even commit sessionStorage to disk.
localStorage does not expire, and data saved in it may remain on a user’s computer indefinitely, which can raise privacy concerns.
Any WebDatabase content stored on the client side is vulnerable to SQL injection and requires proper validation and parameterisation.
Older browser are known to not associate Web Storage with the protocol, making HTTP/HTTPS shared context.
The use of Web Storage to store personal data can potentially lead to privacy and compliance issues.
Encrypt data
It is feasible to perform encryption on the client-side, but it would require the user to input a password each time encryption or decryption is needed. However, the client-side JavaScript operates in an untrusted environment where the cryptographic procedures may not be entirely trustworthy.
Encrypting on the server side is the safest approach, but then the client code cannot read or update it, and so you have reduced your localStorage to a simple cookie.
Performance
The localStorage calls are synchronous.
The Dos and Don'ts of Web Storage
How will your application behave when retrieving any data from localStorage?
Dos:
Treat all data read from localStorage or sessionStorage as untrusted user input.
Validate, encode, and escape data read from localStorage or sessionStorage before rendering it on the page (DOM).
Validate, encode, and escape user input before placing it into localStorage or sessionStorage.
Don'ts:
Store sensitive or personal data in Web Storage, as it is not a secure storage solution.
Use Web Storage data for access control decisions or rely on the JSON objects stored in Web Storage for any logic.
Render stored data on the page (DOM) using a vulnerable JavaScript or library sink.
Allowing file uploads by end users, especially if done without full understanding of risks associated with it, is akin to opening the floodgates for system compromise. If you are designing a new application that accepts file uploads or you already have one please keep reading. Below you will find a list of security requirements that will help you to control the file upload risks in your application.
Here are the top threats to watch out for:
File metadata – The user controlled input like path or a file name can trick an application into copying the file to an unexpected location e.g. control characters in the filename could trick the system to overwrite an important configuration file and cause unexpected behaviour. User controlled metadata like Exif when parsed incorrectly could lead to a buffer overflow and remote code execution. E.g. https://hackerone.com/reports/371135
File size – An unexpectedly large or zero size file can cause an application to overload or fail e.g. botnet could trigger concurrent uploads of a very large file resulting in DDoS.
File content – The content of the file can be use to manipulate the behaviour of the application and allow remote code execution. This depends on how the file is processed server-side. See https://imagetragick.com/
File access – The access rules around uploaded files can be misconfigured, resulting in unauthorised. For example, a misconfigured AWS S3 configuration could result in uploaded files being accessible to the public.
MoSCoW : Must, Should, Could, Won’t
General Requirements
Ref
Requirement
MoSCoW
SFU01
All operations on files obtained from untrusted source must must be carried out in a sandbox. This is to ensure that in the unlikely event of a compromise, malicious actions are limited to the isolated environment, protecting the rest of the system from harm.
M
SFU02
Maintain a strict whitelist of allowed file extensions. Avoid file types that allow of embedding custom objects e.g. PDF, DOC, SVG.
M
SFU03
Run MIME checks to ensure that the file type matches the Content-Type supplied (check file’s magic number or a special magic pattern). Reject all files that do not match the approved types/extensions.
M
SFU04
The user supplied file name must not be used. Rename according to a predetermined convention.
M
SFU05
Make it impossible to overwrite an existing file.
M
SFU06
Ensure that the maximum file name length and the file name size is defined. Never rely on the Content-Length provided, always check the actual size.
M
SFU07
Maintain strong logical segmentation between the component responsible for uploading files and the component responsible for reading the files e.g. create two different apps.
S
SFU08
Log all upload activity. Ensure that both successful and failed attempts are logged.
M
SFU09
Limit the upload functionality to authenticated and authorised users if possible.
C
SFU10
Remove any unnecessary file metadata that may contain personal information before storing. E.g. Exif may contain geolocation, custom tags and other sensitive data.
S
Malware Protections
Ref
Requirement
MoSCoW
SFU11
Files obtained from untrusted sources must be scanned by one or more anti malware scanners to prevent upload of known malicious content.
M
SFU12
Ensure that all incoming images are sanitised using re-writing or content disarm and reconstruction (CDR) especially if file type allows custom object embedding.
S
SFU13
Antivirus and CDR must run in a sandbox.
M
Denial of Service
Ref
Requirement
MoSCoW
SFU14
Implement application specific rate limiting e.g. allow only N-number of concurrent uploads from a single IP.
M
SFU15
Enforce reasonable limits to defend against resource exhaustion e.g. maximum number of files stored per user (space exhaustion), maximum time allowed for the file to be process (CPU exhaustion).
M
SFU16
Detect and prevent automated systems from uploading content. Use captcha or other bot management solution.
S
Storage and Privacy
Ref
Requirement
MoSCoW
SFU17
All files must be encrypted at rest and in transit using strong encryption.
M
SFU18
A random encryption key must be generated per file and wrapped using a master Key Encryption Key (KEK).
M
SFU19
KEK must be securely stored in tamper-resistant hardware security models (HSM).
M
SFU20
Key management including key revocation and mandatory periodic key rotation must be implemented.
M
SFU21
When applicable apply the principle of least privilege such that the file upload component can only write files and doesn’t have read access to the underlying storage.
S
SFU22
Data retention should be implemented. Files older than N-months should be automatically removed.
S
SFU23
The service should be designed to allow seamless processing of ‘right of access’ and ‘right to be forgotten’ requests.
An application security review can be performed at any time in the application lifecycle as long as the design is feature complete and a system or a significant feature is nearing completion. You want all new applications or major changes to the existing software to undergo a review. The purpose of the review is to ensure that the proper security controls are present, that they work as intended, and that they have been invoked in all the right places.
Any appsec review should be a timeboxed exercise. The goal of timeboxing is to define and limit the amount of time dedicated to an activity. I never do reviews longer than one hour regardless of the size of the application. Research shows that engagement starts to drop off quite rapidly after about the first 30 minutes. It is vital to have the right people in the room, a lead developer or anyone who understands the architecture and can efficiently navigate through the code is essential. If one hour is not enough the review can be repeated but there is one rule: The next review must be re-scoped and focus on critical parts of the application only. Use the first review to identify the most critical parts.
The agile appsec review aims to effectively use the 80/20 rule and focus on core activities that result in an exponential risk reduction output. Here are my top 10 things check (no it doesn’t contain all pieces of advice for reviewers, but it is an excellent start especially for web apps):
1. Review the high-level architecture and understand the data flows
At the minimum, a high-level architectural diagram is required that clearly defines boundaries between the system or part of the system showing the entities it interacts with it. The components of the application must be identified and have a reason for being in the application. Data flows should be indicated. This diagram must be documented and updated on every significant change. For high-risk applications, a threat model to determine key risks is required.
2. Check whether input validation is being applied whenever input is processed
Look for all input parameters, things like POST parameters, query strings, cookies, HTTP headers, and ensure these go through validation routines. Whitelisting input is the preferred approach. Only accept data that meets specific criteria. Canonicalization of data before performing input validation must be performed. Lack of canonicalization can allow encoded attack strings to bypass the input validation functions you have implemented. When accepting file uploads from the user make sure to validate the size of the file, the file type, and the file contents as well as ensuring that it is not possible to override the destination path for the file. SQL queries should be crafted with user content passed into a bind variable. The input validation must also check minimum and maximum lengths for all data types received and processed.
3. Check that appropriate encoding has been applied to all data being output by the application
Identify all code paths that return data and ensure this data goes through common encoding functions (gatekeepers) before being returned. This is especially important when output is embedded in an HTML page. The type of encoding must be specific to the context of the page where the user-controlled data is inserted. For example, HTML entity encoding is appropriate for data placed into the HTML e.g. <script> is returned as <script> in the body. However, user data placed into a script requires JavaScript specific output encoding and URL requires url encoding. A consistent encoding approach for all the output produced, regardless whether it’s user-controlled or not, reduces the overall risk of issues like Cross-Site Scripting. You should also check that the application sets the response encoding using HTTP headers or meta tags within HTML. This ensures that the browser doesn’t need to determine the encoding on its own.
4. Verify that authentication credentials, session tokens and personal and sensitive data transmitted over secure connections
Find all routines that transmit data and ensure that secure transport encryption is used. The best practice to protect network traffic against eavesdropping attacks is to deploy TLS everywhere regardless of the sensitivity of data transmitted. Review the effective TLS configuration, especially if the app does not specify it. TLS settings may be inherited from the operating system and require hardening. Legacy protocols like SSLv3 or TLSv1 have known weaknesses and are not considered to be secure. Additionally, some ciphers are cryptographically weak and should be disabled. Finally, the encryption keys, certificates and trust stores must be secured appropriately at rest, as explained in the next section.
5. Enumerate all privileged credentials and secrets used by the application, check how these are protected at rest
Compile a list of credentials used by the application; this includes passwords, certificates, API keys, tokens, encryption keys. Check if secrets are not stored in the source code repositories or left sitting unprotected on disk. While it can be convenient to test application code with hardcoded credentials during development, this significantly increases risk and must be avoided. Secrets should be protected at rest, ideally stored in a central vault where strong access controls and complete traceability and auditability is enforced. User passwords must be stored using secure hashing techniques with robust algorithms like Argon2, PBKDF2, scrypt, or SHA-512. Simply hashing the password a single time does not sufficiently protect the password. Use iterative hashing, combined with a random salt for each user to make the hash strong.
6. Review that authentication is implemented for all pages, API calls, resources, except those specifically intended to be public
All authentication controls should be centralised and self-contained, including libraries that call external authentication services. Check that session tokens are regenerated when the user or service authenticates to the application and when the user privilege level changes. All types of interaction both H2M and M2M, internal and external, service to service, frontend to backend, all must be authenticated. A modern application must not rely on trust boundaries defined by firewalls and network segmentation - never trust, always verify.
7. Review how authorisation has been implemented and ensure that its logic gets executed for each request at the first available opportunity and based on clearly defined roles
Check that all authorisation controls are enforced on a trusted system (server-side). Make use of a Mandatory Access Control (MAC) approach. All-access decisions must be based on the principle of least privilege. If not explicitly allowed, then access should be denied. Additionally, after an account is created, rights must be explicitly added to that account to grant access to resources. Establish and utilise standard, tested, authentication and authorisation services whenever possible. Always apply the principle of complete mediation, forcing all requests through a common security “gatekeeper”. This ensures that access control checks are triggered whether or not the user is authenticated. To prevent Cross-Site Request Forgery attacks, you must embed a random value that is not known to third parties into the HTML form. This CSRF protection token must be unique to each request. This prevents a forged CSRF request from being submitted because the attacker does not know the value of the token.
8. Review the application’s logging approach to ensure relevant information is logged, allowing for a detailed investigation of the timeline when an event happens
The primary objective of error handling and logging is to provide a useful reaction by the user, administrators, and incident response teams. Check that any authentication activities, whether successful or not, are logged. Any activity where the user’s privilege level changes should be logged. Any administrative activities on the application or any of its components should be logged. Any access to sensitive data should be logged. While logging errors and auditing access is important, sensitive data should never be logged in an unencrypted form. Logs should be stored and maintained appropriately to avoid information loss or tampering by an intruder. If logs contain private or sensitive data, the definition of which varies from country to country, the logs become some of the most sensitive information held by the application and thus very attractive to attackers in their own right.
9. Review how error and exceptions are handled by the application to ensure that sensitive debugging information is not exposed
Review the exception handling mechanisms employed by the application. Does the application prevent exposure of sensitive information in error responses, including system details, session identifiers, software details? Error messages should not reveal details about the internal state of the application. For example, file system paths and stack information should not be exposed to the user through error messages. Given the languages and frameworks in use for web application development, never allow an unhandled exception to occur. The development framework or platform may generate default error messages. These should be explicitly suppressed or replaced with customised error messages as framework generated messages may reveal sensitive information back to the user.
10. Check if the application takes advantage of the security HTTP response headers
This is important for web applications and APIs consumed by browsers or HTTP clients. The security-related HTTP headers give the browser more information about how you want it to behave. It can protect clients from common client-side attacks like Clickjacking, TLS Stripping, XSS. Security headers can be used to deliver security policies, set configuration options and disable features of the browser you don’t want to be enabled for your site. Look for the X-Content-Type-Options: nosniff header as explained earlier to ensure that browsers do not try to guess the data type. Use the X-Frame-Options header to prevent content from being loaded by a foreign site in a frame. Content Security Policy (CSP) and X-XSS-Protection headers help defend against many common reflected Cross-Site Scripting (XSS) attacks. HTTP Strict-Transport-Security (HSTS) enforces secure (HTTP over SSL/TLS) connections to the server. This reduces the impact of bugs in web applications leaking session data through cookies (section 4) and defends against Man-in-the-middle attack.
The output of the review is a written record of what transpired, list of issues identified and corresponding risk levels along with a list of actions that named individuals have agreed to perform to mitigate it. This is a very crucial part of effective review that often gets overlooked.
Risk management is fundamental to securing information, systems, and critical business processes. You can’t effectively and constantly manage what you can’t measure, and you can’t measure what you haven’t defined. Basic risk management can be much more effective with clear and concise definition. Here are a couple of the most important ones:
Control is a measure that is modifying risk.Controls can be split into strategic, tactical and operational.
Strategic controls are usually high level, such as risk avoidance, transfer, reduction and acceptance.
Tactical controls determine a course of action such as preventative, corrective and directive.
Operational controls determine the actual treatment such as technical, logical, procedural or people and physical or environmental.
Likelihood is the chance of something happening. It should be used instead of possibility as many things are possible and likelihood gives no indication wether a particular security event is actually likely to take place.
Probability is the measure of the chance of occurrence as a number between zero and one.
Resilience is the adaptive accapacity of an organisation in a complex and changing environment.
Qualitative risk assessment are subjective and generally expressed in terms such as ‘high’,‘medium’,‘low’. This method should be avoided as it renders risk assessments unreliable.
Quantitative risk assessment is generally expressed in numerical terms such as financial values or percentages of revenue. These provide a more accurate measurement of risk and are usually more time consuming to undertake.
Residual risk is the remaining after risk treatment and once all other risk treatment options have been explored. It is normal to accept or tolerate this since further treatment might be prohibitively expensive or have no effect.
Risk is the effect of uncertainty on objectives. Risk is the product of consequence or impact and likelihood or probability.
Risk acceptance or risk tolerance is the informed decision to take a particular risk.
Risk analysis is the process to comprehend the nature of risk and to determine the level of risk.
Risk appetite is the amount and type of risk that an organisation is willing to pursue or retain.
Risk avoidance is an informed decision not to be involved in, or to withdraw from an activity in order not to be exposed to a particular risk.
Risk management is a coordinate activity to direct and control and organisation with regard to risk.
Risk modification is the process of treating risk by the use of controls to reduce either the consequence/impact or the likelihood/probability.
Risk register is a record of information about identified risks.
Risk transference is a form of risk treatment involving the agreed distribution f risk with other parties. One of the risk treatment options is to transfer the risk to or to share it with a third party. This doesn’t however change the ownership of the risk, which remains with the organisation itself.
Risk treatment is the process to modify risk. Treatment may involve risk transference or sharing, risk avoidance or termination.
Stakeholder is a person or organisation that can be affected by a decision of activity.
Threat is a potential cause of an unwanted incident which may result in harm to a system or organisation. Threats are usually manufactured (whether accidental or deliberate) and are different from hazards or natural events.
Threat vectors is a method or mechanism by which an attack is launched against an information asset.
Threat actors is a person or organisation that wishes to benefit from attacking an information asset. Threat actors mounts the attacks. Threat sources ofter pressurise threat actors to attack information assets on their behalf.
Vulnerability is the intrinsic property of something resulting in susceptibility to a risk source that can lead to an event with a consequence. Vulnerabilities or weaknesses leave it open to attack from a threat or hazard.
Adopting a coaching mindset in most circumstances adds significant benefits to any security leader and even more importantly helps build successful security teams. These benefits include improved engagement, motivation and team morale. It delivers greater accountability and communication. Security projects and tasks can be performed faster freeing up the valuable time leaders require to operate at the correct strategic level.
It is the most effective when an employee has the skills and ability to complete the task at hand, but for some reason is struggling with the confidence, focus, motivation, drive, or bandwidth to be at their best, coaching can help.
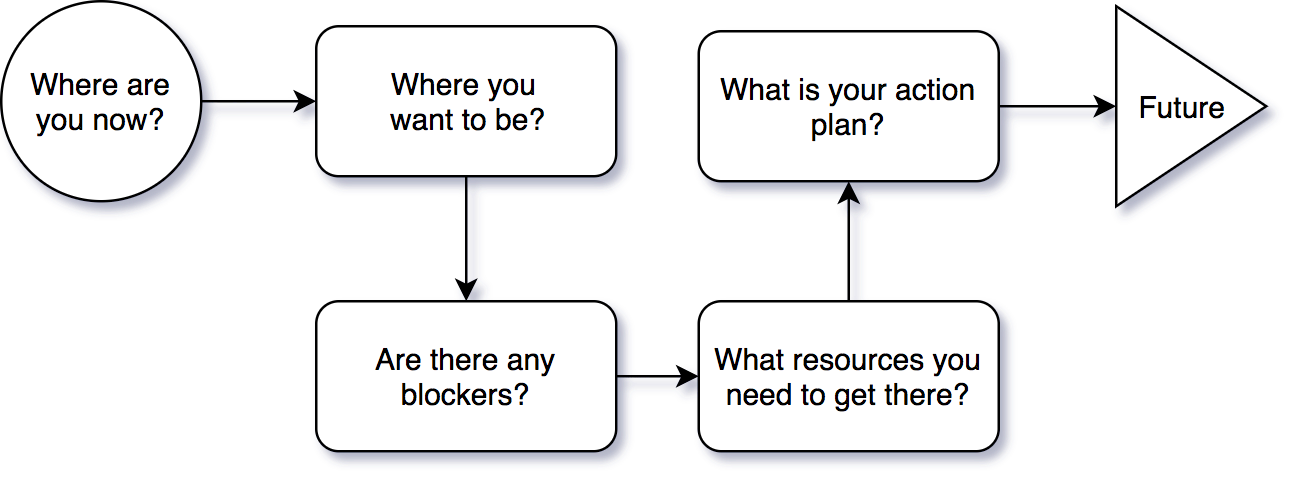
I use the below process in my coaching sessions with great success. I steer the conversation towards the distinctive phases shown below and look for the meaning behind responses provided. In reality, a coach is there to guide you toward your own solutions, and hold you accountable for taking action.
The most important way to achieve this is by asking your coachee the right questions. These great questions may force someone to look at their situation from another perspective, thereby encouraging the breakthrough they need to succeed.
Here is a list of effective questions I use at each stage of the coaching process:
Now
What will be useful for us to talk about today?
How long have you been thinking of this?
What is most important to you about this?
On a scale of 1 - 10 how important is this to you?
Do you notice any patterns?
Future
If you had this the way you wanted what would that be?
What do you really want here?
What is your definition of success?
How will you know you have what you want?
Can you start and maintain this?
Are you in control of the outcome?
Blocks
What stops you from achieving this?
How can you do it anyway?
What do you believe is currently stopping you?
Is it possible to do it?
Is it right for you to do it?
Where are you either too flexible or too uncompromising about this issues?
Is there anything else stopping you?
Resources
What will help you achieve this?
What resources do you need?
What resources do you already have?
Are there any similar situation you have resolved in the past?
At your best, what would you do right now?
Action
What will you do about this?
What practical actions you can take right now?
What will your first step be?
When will you start?
How will you like to let me know you have achieved these actions?
Storing cleartext passwords is a bad idea. Passwords should be irreversible when in storage. When passwords are stored as original cleartext, anyone who has access to the underlying storage system will also get access to all the accounts. Cryptographic hashes should be used to protect such sensitive authentication data at rest.
Hashing
The process of hashing takes the original password and transforms it using a one-way function to data of a fixed size. A few different types of hashing are out there. The most common are MD5, SHA-1, SHA-256. In recent years a number of known cryptographic weaknesses have been identified making some of these algorithms unusable as a message digest. However, not all of these apply in the context of password hashing. The main problem being these algorithms are too fast. You can address this by implementing iterative hashing, where you hash the password multiple time. You should pick the number of iterations based on time. I suggest a minimum of 200 ms for the function to complete.
Rather than building a bespoke iterative hashing, it’s a much better idea to use a hashing method that is considered a de facto standard for password storage. There are many robust algorithms out there that come with configurable work factor. To name the most popular here:
Bcrypt
PBKDF2
Scrypt
Argon2
Argon2 is the latest and was selected as the winner of the Password Hashing Competition in July 2015. This should be the default choice for any new application.
Storage format
The evolution of parallel computing enables new and faster attacks against password hashing. You should carefully choose the format used to store hashes. Cryptographic algorithms change over time. Even if an algorithm is still secure, you should increase the work factor every year to keep up with Moore’s law.
Here is an example of a format used by GNU C library:
The rounds=N is the number of hashing rounds actually used. The $salt stands for the up to 16 characters of random salt. The $hash part is the actual hashed password using the $id algorithm. The length of the hash depends on the algorithm used.
This is just an example and you can come up with your own scheme. However, extending the existing one with new algorithms like Argon2, PBKDF and assigning them a new $id will make things more clear. It will be also much easier to understand for anyone familiar with this storage format.
Hashes are often stored in a database. It makes sense to store other metadata about the account too:
Last password change time and date
Last login time and date
Active / inactive / locked flag
Future proofing
As the time passes you will end up in a situation where the existing password storage solution becomes cryptographically outdated and must be updated either by changing the work factor or the algorithm used. You should built-in the ability to upgrade in place without adversely affecting existing user accounts right from the start. The best approach is to upgrade it upon successful authentication. When a user attempts to log in, the application can hash the password using the old (weak) and the new (secure) algorithm. If the old hash matches the existing database records, then the new stronger hash is stored in the database replacing the old, weak one. With the additional metadata, you can measure the uptake and decide what to do with users who haven’t logged in since the change was made. An email asking users to log in back is a good idea. It makes sense to lock the account if it hasn’t been used for some time, e.g. one year.
Password reuse
Two in three people reuse the same password for multiple accounts. If a password is compromised elsewhere, it can be correlated by username or email address to other services using the same password, thus propagating the threat. It makes sense for any modern application to check the user passwords against existing data breaches. The Pwned Passwords is such a database that is available for both offline and online use. The public Have I Been Pwned API uses a k-anonymity model where the password can be hashed client-side with the SHA-1 algorithm, and only the first 5 characters of the hash are shared. Alternatively, you can download the entire Pwned Password list, upload it to a database and create a local service. Unlike the public API, the local service will require periodic updates to ensure it contains the latest breached hashes.
Go passwordless
Adopting a risk avoidance strategy for password storage may be an option for modern applications. This is only possible if you eliminate risk by withdrawing or not becoming involved in the most high-risk activity of user authentication. One such option is to implement Social Login. From the user’s perspective, it provides a frictionless way to login; it also eliminates the need to store and process passwords by the application. There are pros on cons of using social login. I’m not going to discuss it here but just to mention a few like the loss of control to a third party, privacy concerns and long-lived access tokens that may not be suitable for all applications.
Another approach is to provide a one time password (OTP) using an out-of-band channel (e.g. push notification, email, SMS) upon login. This method is as good as the security of the out-of-band channel. Also, the OTP can sometimes be delayed by hours depending on the delivery mechanism used. This may not be acceptable in some scenarios.
Finally, you can trade the password storage for cryptographic material storage. WebAuthn (Web Authentication) is a new emerging standard for authenticating users to web-based applications and services using public-key cryptography. A public key and randomly generated credential ID must be still stored. However, even if exposed the risk is minimal, public keys by designed to be openly shared. Additionally, due to a much larger keyspace, compared to average password complexity, public keys are considered infeasible to brute force at this time (keys 2048 bit and larger). All major browsers are adopting WebAuthn on both mobile and desktop. Once it becomes part of the core iOS and Android platform will mean that devices like a phone can provide us with biometric verification and WebAuthn will slowly replace traditional passwords. Watch this space closely.
Secure Sockets Layer (SSL) has been unquestionably the most widely-used encryption protocol for over two decades. SSL v3.0 was replaced in 1999 by TLS v1.0 which has since been replaced by TLS v1.1 and v1.2.
In April 2015, SSL and early TLS were removed as an example of strong cryptography in PCI DSS v3.1. For this reason, PCI-DSS version 3.2 has established a deadline for the migration of SSL and TLS, set on June 30, 2018.
Unfortunately, TLS v1.0 remains in widespread use today despite multiple critical security vulnerabilities exposed in the protocol in 2014.
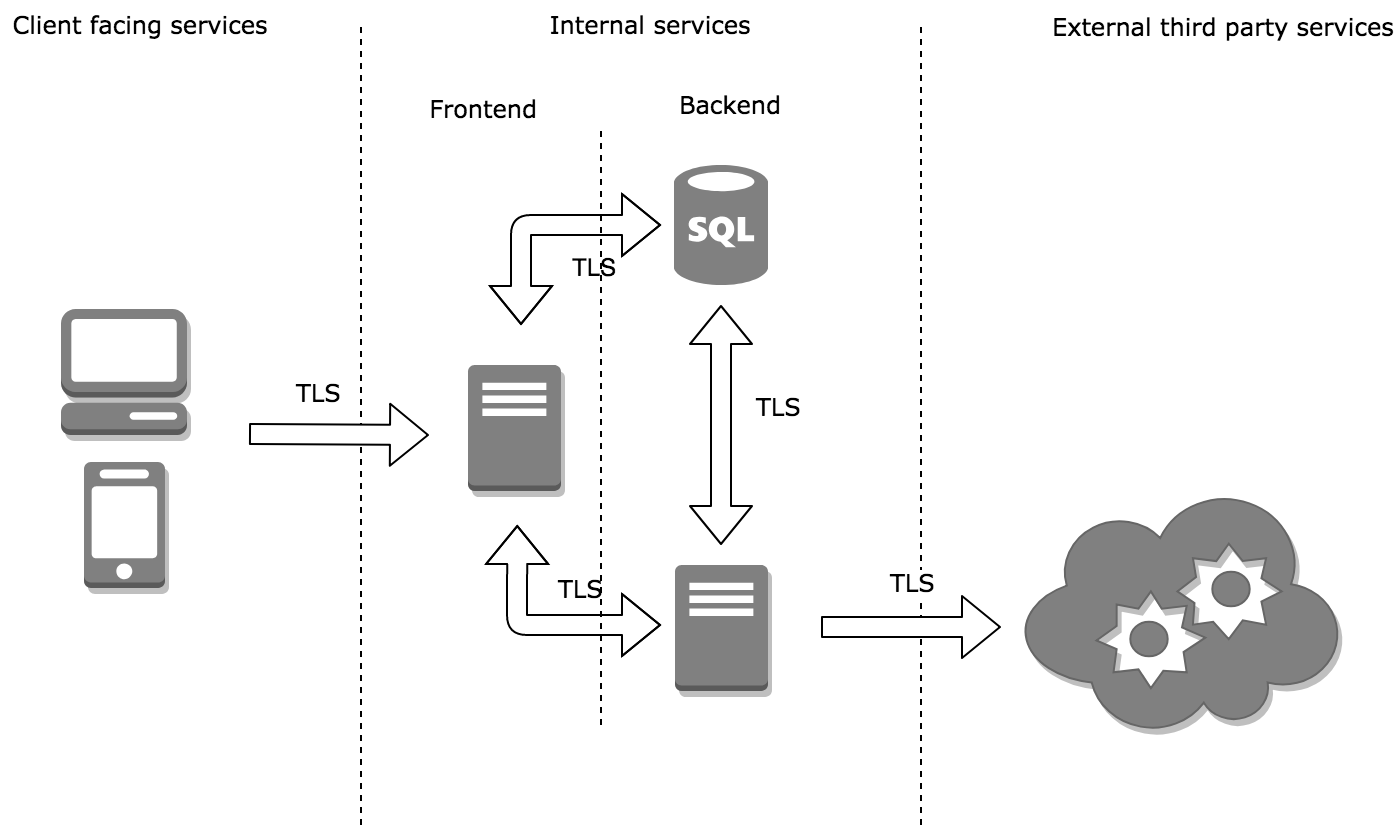
It’s not always a straightfoward task to establish where in your organisation TLSv1.0 may be used. It’s common to look at the external footpring only overlooking any internal and outbound communication.
No matter how complex your environment is you can always divide it into smaller segments and look at three major places:
Inbound
Most vulnerablity scanners have signatures to detect legacy SSL and early TLS versions. You can scan all of your external hosts to enumerate services that need fixing. Here’s a sample finding from Qualys:
You can run a simple search all your assets managed by Qualys,
1
vulnerabilities.vulnerability.qid: 38628
Alternatively, you can use nmap or other tools like testssl.sh
Web and Mobile Clients
You can inspect your web analytics tool to get some understanding of the clients that still rely on TLSv1.0. Create a report to show stats from the below clients:
Android 4.3 and earlier versions
Firefox version 5.0 and earlier versions
Internet Explorer 8-10 on Windows 7 and earlier versions
Internet Explorer 10 on Win Phone 8.0
Safari 6.0.4/OS X10.8.4 and earlier versions
From my experience, the numbers will be low, often below 1%. Most users have modern browsers and phones that support TLSv1.2. There will be some older Android devices and general noise from bot traffic often using spoofed headers.
API Clients
If your company provides external APIs used by customers to integrate with your services you may need to do more work before deprecating early-TLS. There’s usually no analytics available for such integrations, the client-side systems owned by customers may not be regularly updated. Finally, the most popular software frameworks like the .NET default to TLSv1.0 even though a higher version is supported.
Here are a few popular software development languages and frameworks that need upgrading, recompiling or a custom configuration change to support TLSv1.2
.NET 4.5 and earlier
Java 7 and earlier versions
OpenSSL 1.0.0 and earlier (Ruby, Python, other frameworks that use OpenSSL)
The best way to gain some visibility into the clients still negotiating early TLS on your systems is to enable extra logging on the edge web servers or load balancers. If you use Nginx simply add $ssl_protocol to your log_format or %{SSL_PROTOCOL} for Apache.
Here’s a sample log entry with SSL protocol version and cipher specs logging enabled:
If your infrastructure sits behind a content delivery network like Akamai or Cloudflare you need to enable the extra logging there. This is not always a simple task. For example on Akamai to enable this additional logging, you need to select a particular log format that includes “Custom Field” in your Log Delivery Service (LDS):
In Akamai’s property manager for you site you need to again enable Custom Log Field and specify a couple of special variables that should be captured:
Here’s a sample log entry from Akamai with SSL scheme, protocol and cipher:
1
2016-07-24 13:49:41 127.0.0.1 GET /www.example.com/1531720867000.js 200 5109 1 "https://www.example.com/example.aspx" "Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko" "-" "https|tls1.2|ECDHE-RSA-AES256-SHA384" 10.0.0.1 1 "trTc_19843||"
With the TLS details now being logged, you can use your favourite log searching tool to identify clients that need to be upgraded before you withdraw support for early-TLS.
Outbound
It is not always straightforward to detect outbound connections that still use TLSv1.0. Inspecting the client side configs don’t always show the problem. For example, clients that use .NET 4.5 and SChannel default to TLSv1.0 even though the underlying operating system fully supports TLSv1.2.
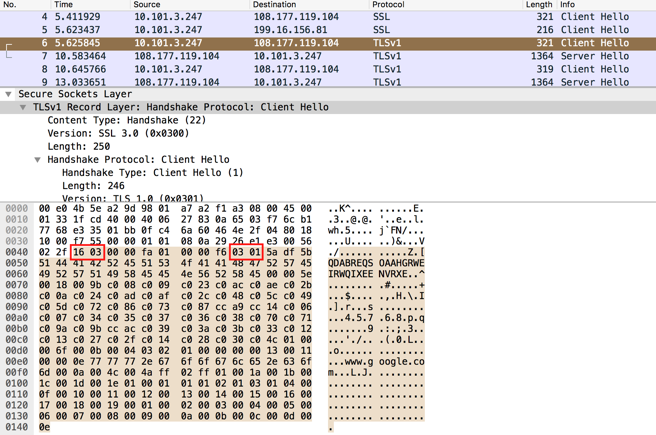
I found that the most effective way of detecting such clients is to run a packet capture at the egress points of the network.
I use BPF filter only to capture SSL handshakes that include the protocol version negotiated. With this approach, you can run the dump for longer, with less risk of causing performance or disk space issues. Running the capture for a day or week can uncover clients that only sporadically connect e.g. batch jobs.
I suggest running the dump for a short period of time first, e.g. 1 minute to get the feeling of the volume of traffic you will capture. If you are happy with the size, then let it run for longer e.g. 24h to catch the full day’s traffic.
Here’s a sample command to capture TLSv1.0 and SSLv3.0 ClientHello/ServerHello packets.
1
tcpdump -s0 -i any "tcp and (tcp[((tcp[12] & 0xf0) >> 2):2] = 0x1603) and ((tcp[((tcp[12] & 0xf0) >> 2)+9:2] = 0x0300) or (tcp[((tcp[12] & 0xf0) >> 2)+9:2] = 0x0301))" -w /tmp/TLShandshake.pcap
where:
1234567891011121314151617181920212223242526
record type (1 byte)
/
/ version (1 byte major, 1 byte minor)
/ /
/ / length (2 bytes)
/ / /
+----+----+----+----+----+
| | | | | |
| | | | | | TLS Record header
+----+----+----+----+----+
Record Type Values dec hex
-------------------------------------
CHANGE_CIPHER_SPEC 20 0x14
ALERT 21 0x15
HANDSHAKE 22 0x16
APPLICATION_DATA 23 0x17
Version Values dec hex
-------------------------------------
SSL 3.0 3,0 0x0300
TLS 1.0 3,1 0x0301
TLS 1.1 3,2 0x0302
TLS 1.2 3,3 0x0303
You can analyse the captures with thsark and command line tools:
1
tshark -r TLShandshake.pcap -q -z conv,ip
Here’s an example that extracts certificate’s common name together with the internal client IP and sorts by the number of connections:
It’s very likely that some internal services in your environment will use older TLS to communicate. However, this scenario may be the easiest to fix provided you have a test environment that closely mirrors production. You can run a vulnerability scan to determine endpoints that need fixing and apply the changes to your test environment first. You can then reconfigure or upgrade clients that no longer connect.
You may still need to run tcpumps in strategic places in your production environment to validate that early TLS has been successfully eradicated. From my experience, services that use proprietary protocols or capable of upgrading the connection to TLS (like STARTTLS) may not always show up on vulnerability scans. In this scenario, a manual inspection of the configuration and TLS handshake dumps goes a long way.
In this post, I’m going to touch on all the aspects of building an enterprise security program. This is a vast topic, and I could have spent pages and pages explaining each element of a successful program. However, the goal of this post is to merely define the necessary steps and provide a roadmap to get you started.
Here is a basic outline for an enterprise security program:
Risk Assesment
Plan of Action
Tactical and Strategic Goals
Security Budget
Security Policies and Procedures
Vulnerability Management
Training and Awareness
Quarterly Security Reviews
Anual Program Review
The idea of building a security program from scratch is a daunting task. You need to have a comprehensive background in IT and security to be successful. Knowledge and expertise of IT is 90% of this job. Most of your time you will be evaluating technologies, advising business teams, deciding what is or is not a risk and finally directing security priorities and implementations.
Risk Assesment
The goal of the risk assessment is to identify where your risks are. First, you need to know where the sensitive data resides that you need to protect. Effective asset management helps with identification where the critical assets are. You need to focus on the sensitive data first. If you perform credit card processing that you need to start with PCI DSS. A PCI DSS gap analysis is usually the first step to understand the compliance status. If you store and process personal data (PD) than CIS Critical Security Controls (CSC), risk assessment or a more detailed NIST using SP 800 series would be recommended together with a GDPR gap analysis.
Plan of Action
The outcome of the above risk analysis will feed into the plan of action. This is mainly focused on hight and mid-level risks. The plan of action would include all the major risks, mitigation strategy, budget requirements, timelines. In many cases, this is also referred to as a gap assessment.
Ref
Risk
Priority
Mitigation
Budget
Milestones
Tactical and Strategic Goals
A typical security strategy is a combination of both short-term tactical and long-term strategy. You are faced with a continually changing landscape so tactical planning should be limited to 6 months and strategic to max 12-24 months.
The strategic plan looks beyond the tactical focus. Some problems and risks will take a long time to mitigate.
The output of Risk Assessment is used in the plan of action based on the risk levels identified. Then you prioritise the plan of action to create a tactical and strategic security plan. The prioritisation is based on the sensitivity of data you process.
Security Budget
The security budget should closely map to the tactical and strategic security plans. It is something that takes a lot of consideration. You need to negotiate all products you buy. Security products are always overpriced; this is a fact. Look at the open source products first to understand functionality that is already available out there for free. When you select a product, the features should come first and cohesion second. Let’s face it you cannot overlook the support side of the equation. Even most sophisticated and functional open source products will fail if you don’t have the right people to support it.
Security Policy
There are two significant policies that every organisation should have. You should focus on getting these two right before moving on to the rest of security policies for your organisation.
Data Classification
You need to classify all data within the organisation appropriately. Sensitive data may be defined as PCI, PD or health information. You need to know where the sensitive data resides. It makes sense to divide the data into tiers based on sensitivity classification. For example:
Tier 0 - data that could be used to prejudice or discriminate against specific individuals. This includes ethnic origin, political membership, health information, sexual orientation, employment details or criminal history. Also payment card data, genetic data, biometric data and authentication data like passwords.
Tier 1 - data that on its own can be used to identify specific individuals. E.g. names, addresses, email addresses, phone numbers, copies of passports or drivers' licences.
Tier 2 - any data when aggregated with other tier-2 or tier-1 may allow specific individuals to be identified. E.g. IP addresses, transaction metadata and geolocation data.
Tier 3 - data that may, when aggregated with Tier-2 or tier-1 data, but not with other T3 data, allow specific individuals to be identified. E.g. Device ID, Advertising IDs, hashes, cookies and search string data.
The data classification policy should make a clear distinction between data types to help your organisation. It should describe the proper handling of each type.
Data Protection
You want to document a data protection standard. The document explains how the data is protected, and who should have access to it.
The data protection policy is to ensure that data is protected from unauthorised use or disclosure and complies with data classification policy and best practices and standards.
Vulnerability Management
Vulnerability management is an ongoing approach to the collection and analysis of information regarding vulnerabilities, exploits and possible inappropriate data flows. A comprehensive vulnerability management program provides you with knowledge awareness and risk background necessary to understand threats to the organisation’s environment and react accordingly.
A successful vulnerability management program consists of 5 distinctive steps:
* Determine the hardware and software assets in your environment
* Determine the criticality of these assets
* Identify the security vulnerabilities impacting the assets
* Determine a quantifiable risk score for each vulnerability
* Mitigate the highest risk vulnerabilities from the most valuable assets
Most of the steps in vulnerability management can be automated to some extent with the exception of Penetration Testing. This type of manual testing is the perfect complement to automated vulnerability scanning. Start with a smaller scope and target higher-risk assets. Learn from it and expand the practice.
Security Training and Awareness
Security training is important and should be embedded into several core areas in your organisation:
New hire training
Quaterly or yearly awarness training that includes common threats, spear phishing, whaling, social engineering
Email newsletters, alerts, breaking news that impact staff
Security demos, presentation, seminars, security engineering days
Security wiki, initiatives and changes everyone should know about
I’m afraid organisational culture and human behavior have not evolved nearly as rapidly as technology. If you look closely at recent data breaches you’ll notice that phishing or another social engineering technique at some point during the attack was used. To fight such scams, employees need to be aware of the threats.
Quaterly Security Reviews
The quaterly scurity reviews are citical to ongoing security operations. The larger the team you have the more frequent you should be perfomrning these.
These are perioding checkups to address vulnerability status, progress with risk mitigation, review the policies and procedure.
Here are some of the things you should review.
Vulnerability scan results and remediation
Review penetration testing
Access controls
Policy and Procedures Reiew
Progerss toward the tactial plan
Review the impact of security changes made during the quarter.
Update the executive managemetn and senior leadership
Annual Program Review
This is a great opportunity to step back and see the bigger picture to ensure that the security program is heading in the right direction. Several major tasks must be completed for the annual refresh:
Anuual Risk Assesment (CIS CRC 20, PCI, GDPR)
Update the plan of action
Tactical security plan for the coming year
Budget planning
Conclusion
One of the most important things to understand that there are never enough security resources available to cover all the work.
Prioritisation is necessary, and you want to be highly efficient where you apply your energy and resources. You need to be proficient in getting maximum value out of your efforts to improve security in your organisations. Security professionals need to negotiate hard and often to get things done.
The person responsible for security in any given organisation must have a complete vision of where they want to take the security program.
 >_ Unvalidated input
>_ Unvalidated input